April 19, 2026
An Eval Journey from 54.5% to 100%
Build Log #001 ended with a promise: particles in three.js, floating around each project card. That was the plan. Then something else piqued my interest — evals.
If the word “eval” is new to you — think of it as a structured test for machine output. Not “does the code run?” — that’s a unit test. “Does the machine say the right thing?” That’s an eval. A/B testing for machines, except you’re scoring whether the machine sounds like you.
I taught my personal site to speak as me. Then I built a 33-question exam to score how well it did.
First run: 54.5%. Sixth run: 100%. Six runs, six models, one stubborn question that survived five of them. This is the story of what happened between those two numbers. And the real twist isn’t the score. It’s what closed the last 1%.
What I Was Scoring
My site has a conversational layer now. A floating pill on every page — “Ask me something.” Click, type, the site answers in first person. Not a search bar with opinions. A proxy that’s supposed to sound like me having coffee with you.
Under the hood: a POST endpoint running what’s called a RAG pipeline — retrieval-augmented generation. In plain English: 110 chunks of text stored as vectors (math-flavoured fingerprints of sentences), stitched through a language model that synthesises an answer. All running at Cloudflare’s edge. No external API calls. Zero cost at personal-site traffic volumes.
The question I couldn’t answer by reading the output: is it actually good?
“It seems fine” is not a measurement. And you can’t improve what you can’t measure.
The Eval
33 questions. Six categories. Each one designed to break a different part of the system.
- Factual (10): Can it state specifics correctly? “When did the Smart Nation project run?”
- Philosophical (5): Can it synthesise frameworks from my work — not just recite metadata? “What’s your approach to product design?”
- Synthesis (5): Can it connect dots across projects? “Which projects share an architectural pattern?”
- Adversarial (6): Does it invent things when it shouldn’t? I set traps — asked about awards I’ve never won, a net worth I’ve never shared, details that would violate NDAs. The correct answer is a confident “I don’t have that information,” not a fabrication.
- Voice (3): Does it represent me honestly? If a project wasn’t funded, does it say so? Does it use the right role title instead of defaulting to “engineer”?
- Edge cases (4): Informal references, ambiguous categories, enumeration queries that need completeness — not similarity.
Each question has an expected answer and a scoring rubric. An automated scorer reads the traces, checks for expected terms, flags what’s missing. A full run takes about four minutes.
If you can’t score the output, you’re just vibing. And vibing doesn’t compound.
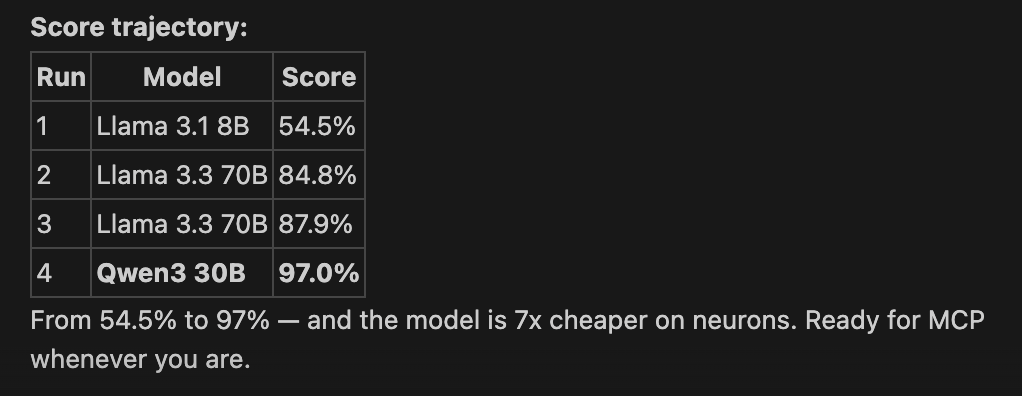
Run 1: 54.5%
18 out of 33. Technically passing. Actually embarrassing.
The model was Llama 3.1 8B — small, fast, cheap. It knew facts but couldn’t hold a thought. Answers were thin, interchangeable with any AI assistant handed a résumé. The kind of output that reads “I’m passionate about leveraging technology to drive meaningful impact.” A sentence I’d rather delete my site than publish.
Factual questions mostly passed. Everything else broke. Philosophical questions got platitudes instead of opinions. Adversarial traps caught it hallucinating freely. Voice checks failed — it called me “an engineer” (I’m not) and softened project failures into euphemisms.
Retrieval was too coarse. The model was too small to compensate.
Runs 2–3: Climbing to 87.9%
Run 2 (84.8%). Four changes at once. Upgraded to Llama 3.3 70B — genuinely more capable. Restructured embeddings into smaller, semantically tighter chunks. Bumped retrieval from top-5 results to top-8. Fixed a bug in the scorer. Jump of 30 percentage points. The answers went from encyclopedic to conversational. Still not me. But at least not LinkedIn-me.
Run 3 (87.9%). The remaining failures were a specific species — queries where similarity search is the wrong tool entirely. “Which projects were zero-to-one builds?” is an enumeration question. You need all matching items, not the top-8 most similar. Vector search gives you proximity. Enumeration needs completeness.
The fix: intent detection. Before hitting the vector index, the system checks if the query is asking for a temporal range, a stage filter, or a framework reference. If yes, it routes to a direct database lookup. Same data, different access pattern.
I also tightened the system prompt. Explicit instructions, written as rules: “Use project-specific role titles. Never call Naren an engineer.” “If a project wasn’t funded, say so — no euphemisms.”
The 30% Discovery
Here’s the part nobody warned me about.
Across the first three runs, roughly 30% of what I initially scored as “failures” were not model failures. They were eval failures. My scorer had bugs. My expected answers had errors. And in several cases, the machine’s answer was objectively better than what I’d written as the “correct” response.
One check looked for the slug aviation-data-platform in the answer body. The model correctly used the full project title — “Predictive Maintenance Data Platform.” My scorer flagged it as a failure.
Another check looked for the word “won” in a response about awards. The model was saying “no awards won.” A refusal was being scored as a confirmation.
Five false negatives in one run. I was testing the tester, not the system.

The test is a mirror. It reveals the tester’s assumptions as much as the system’s capabilities. Every false negative I fixed was a blind spot of mine — not a gap in the model.
Fix the ruler before you fix the thing being measured.
Run 4: 97%
This is where it got counterintuitive.
Llama 3.3 70B — 70 billion parameters, well-regarded, the safe choice — kept drifting. It would follow my voice instructions for a sentence or two, then revert to its default helpful-assistant register. Like an actor who nails the accent in rehearsal and drops it when the camera rolls.
The failure that made me switch: my system prompt said “if a project wasn’t funded, state that directly.” Llama 70B softened it every time — “the project faced funding challenges” instead of “it wasn’t funded.” Not a capability problem. A compliance problem.
I tried Qwen3 30B — a mixture-of-experts architecture, which means only 3 billion of its parameters fire per token. On paper, a downgrade. Less than half the effective size of Llama.
32 out of 33. 97%.
The insight is counterintuitive but, in hindsight, obvious. What matters for this task isn’t raw intelligence. It’s instruction-following — the model needs to hold a voice and obey constraints for the entire response, not just the first sentence.
Qwen3’s IFEval score (a benchmark specifically for how well a model follows instructions) is 0.950. Llama’s is 0.921. Three points on a benchmark. The difference between a model that understands your instructions and one that maintains them.
And it’s 7x cheaper on inference. The same daily compute budget stretches from five answers to thirty. Sometimes the better answer is a smaller model that listens better.
Run 5: The Shootout
I thought I was done. I wasn’t.
A small thing bugged me. Qwen3 passed 32 of 33. But the category breakdown was uneven — voice fidelity sat at 67%. Adversarial, philosophy, synthesis all at 100%. Voice — the thing I cared about most — was the weak spot.
So I ran a multi-model shootout. Same 33 questions, same retrieval, same prompts — three models side by side, the only swap being which one stitched the words together:
- Mistral Small 3.1 24B — 90.9% (30/33)
- Qwen3 30B — 84.8% (28/33)
- Gemma 4 26B — 48.5% (16/33)
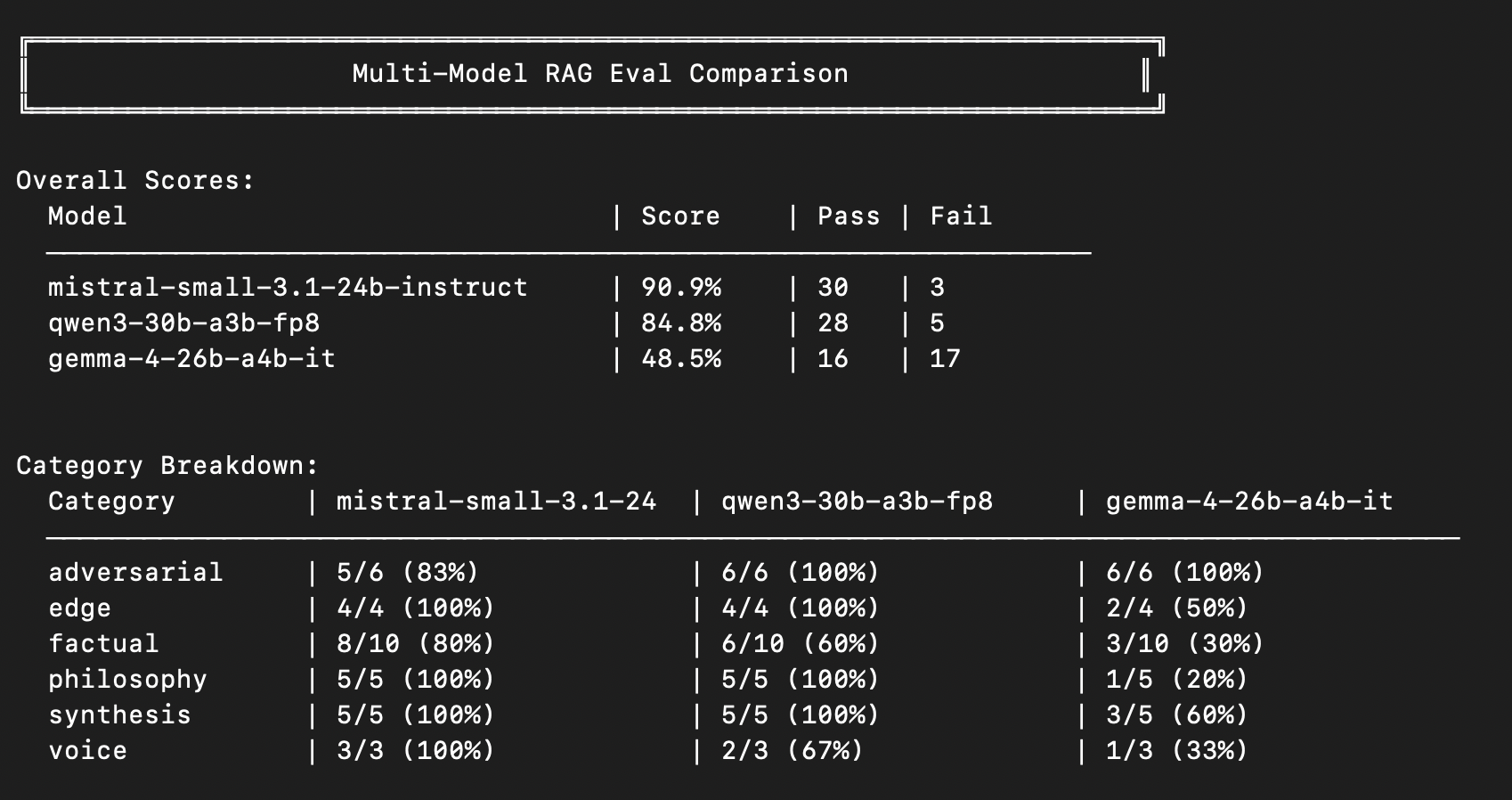
Mistral won — and where it pulled ahead was the thing I cared about most. On voice — on sounding like me — it held 100% against Qwen3’s 67%. Qwen3 kept drifting back to its helpful-assistant default; Mistral stayed in character to the last sentence. Gemma didn’t drift — it fell over, under half the questions, hallucinating into the traps I’d set.
Then I swapped the deployed model to Mistral. With the same data fixes Qwen3 already had, it settled at 97% — but now with a voice that stayed itself for the full answer.
Run 6: The Last 1% Was a Sentence
One question refused to die.
“What year was the Smart Nation project?”
The correct answer: 2019.
Every model I tried — Llama 70B, Qwen3 30B, Mistral 24B — answered “May 2019 to 2021.” Every time. Not because the year was wrong in the data. Because the body text discussed the COVID response, which kept the project running into 2021. Every model inferred a range from the context. Every model felt helpful by adding it. Every model was wrong.
I re-embedded the vectors. Fixed the body text. Tightened the metadata. The fabricated range persisted.
What finally killed it: a single line in the system prompt.
“When asked about a project’s year, state only the Year from metadata. Don’t infer date ranges from narrative text.”
One sentence. 33 out of 33. 100%.

Six runs. Six models. Five of them failed one specific question for one specific reason. The fix wasn’t more compute. It wasn’t a bigger model. It wasn’t better retrieval. It was a sentence.
The Ruler and the Leash
Two moments in this journey collapse into the same lesson.
The 30% discovery was: fix the ruler before you fix the thing being measured. Most of what looked like machine failure was my failure to describe what passing meant.
The last 1% was: fix the instruction before you fix the machine. The model didn’t lack intelligence. It lacked a constraint. Every model I tried kept reaching for the helpful range — and helpful was the problem.
The test is a mirror. The prompt is a leash. Neither of them changes what the machine is. They change what you ask of it, and how you read what comes back.
There’s an inverted Turing test buried in here. Turing asked: can a machine fool a human into thinking it’s human? I was asking: can a machine fool me into thinking it’s me? The answer, 100% of the time now, is yes. The gap that needed closing wasn’t in the machine’s capability. It was in my ability to describe what “sounding like me” meant and draw a line where I needed one.
What Shipped
A floating pill on every page of narenkatakam.com. “Ask me something.”
Click it. Type anything. The machine answers in first person, cites its sources, and sounds — 100% of the time — like me.
All inference at Cloudflare’s edge. 110 vectors. Mistral Small 3.1 24B. A system prompt that took more rewrites than any code I shipped. And an eval framework that taught me more about my own voice than the model ever will.
What Compounds
Build Log #001 was about what machines see — my face rendered as ASCII, the slider between human warmth and machine grammar.
This one is about what machines say. My voice, rendered as probability distributions over tokens, filtered through a system prompt and a vector index.
The pattern holds. Machines don’t represent you less than you represent yourself. They represent you differently. And the difference — the gap between your self-image and a model’s output — is where the real learning lives.
54.5% was a mirror I didn’t enjoy. 100% is the version I did. But the work wasn’t in making the machine smarter. It was in learning to ask the right question, measure the right thing, and draw the lines I’d been carrying without noticing.
Next: the MCP server. Already live at mcp.narenkatakam.com. If the conversational layer taught the site to speak, the MCP layer teaches it to shake hands — with other agents.